360有权抓取百度上的网民作品
百度与360公司爬虫机器人不正当竞争纠纷案受到外界关注。日前,北京市第一中级法院驳回了百度有关不正当竞争的诉求,表明百度单方面利用歧视性Robots协议打击竞争对手的行为不会被公众和法庭所支持,而360则可以继续抓取百度的网站内容。
抛开爬虫定义、Robots协议的晦涩专业,此案的实质是海量信息的搜索与隐私权保护的中间规则。形象的说,它如同门牌号码,页面所有者也即户主可以盖牌子选择不准访问,以保护隐私。而搜索,实则就是通过门牌号码,获得网页地址,从而帮助读取。

纠纷案之争,在于百度将其旗下百度知道、百度文库、百度贴吧等网站内容修订规则、盖上牌子,只允许360以外的搜索引擎访问,而360的搜索爬虫则对这些内容进行了访问。乍一看,似乎是360强闯民宅,乱翻了百度牌子。
然而,当我们对这些网站内容进行界定,就发现这些都是网民上传、发表的内容,换言之著作权属于网民,而非百度,其上传和发表是一种默认的共享行为,理应有被访问的门牌号。这些内容犹如零散住户,百度充其量只能算是多家“小区”的物业管理人员。物业管理员对邮递员的区别对待,是不恰当的。
被翻与不被翻的Robots协议,在于尊重所有者的隐私权;然而可翻与不可翻的区别对待,显然违反了开放、共享的互联网精神。开放、分享的互联网精神是互联网核心基础,更是其迅猛发展的驱动所在。无视这种开放与共享,就会形成大型网站绑架上传资料者的局面,就会导致山头林立,形成更多的信息沟壑,这显然无益于互联网的健康发展。
不仅如此,互联网精神所鼓励的自由竞争和创新,更应建立在平等公平的竞争秩序基础上,而绝不应以技术、先行垄断行“丛林法则”之实。通过先入优势构建技术壁垒,塑造恃强凌弱的竞争格局,这势必加剧垄断局面的形成,这显然有违平等公平的竞争秩序。

进而言之,在绝对的垄断和利益的驱使下,独此一家的搜索本身也可能异变成为一种阅读、推广的绑架。若到这种情形下,你想看的或许都会异变成它想让你看的,届时被掩盖的也许就不仅仅是资料分享者的门户牌子了。

Robots协议不应成为市场竞争维护垄断的工具
奇虎360进军搜索市场之后,搜索巨头和360之间的关系似乎更加剑拔弩张。近日,360公司和搜索巨头公司关于搜索引擎爬虫行为争议再度引发业界关注。有分析人士认为,Robots协议不是行业法规或标准,不存在违反与不违反的问题,更不应该成为用于搜索市场竞争的武器。
2012年8月16日,360正式推出搜索引擎,并在上线6天后,占据中国搜索市场10%的份额,成为仅次于搜索引擎的第二大搜索流量来源。但不久,360搜索遭到反制措施,所有来自360搜索的用户请求强行跳转,用户需要二次点击才能得到搜索的结果。
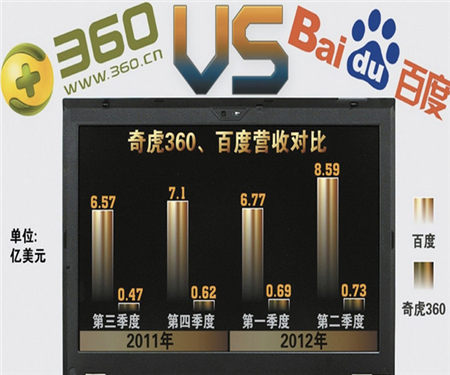
技术专家指出,知道、百科、贴吧等产品在Robots文件中禁止360搜索抓取索引。然而,国内最大的搜索引擎仍允许包括谷歌、必应、搜狗、搜搜在内的所有搜索引擎抓取索引上述内容。通过Robots协议仅阻止360搜索抓取索引,是把Robots协议当成不正当竞争的工具,目的是打击和封堵360搜索。
单方面强调Robots协议的作用,试图作为限制竞争对手的标准,而是否任何一家搜索引擎也如他们所描述的那样遵守Robots协议呢?

据悉,Robots协议由荷兰籍网络工程师于1994年首次提出,是一个被放置在网站中的.TXT文件,为搜索引擎爬虫做出提示,设置允许与不允许两种语句,网络爬虫据此“自觉地”抓取或者不抓取该网页内容。
但Robots并不是一个规范,而只是一个约定俗成的协议。Robots协议创始人明确提出Robots协议是一个未经标准组织备案的非官方标准,不属于任何商业组织。如果该协议被当成市场竞争攻击,所有现在和未来的机器人(搜索引擎)不必遵从Robots协议。
业内人士在接受记者采访时认为,Robots协议本是为了搜索引擎更有效的的索引到内容结果页、内容网站服务器等资源免受爬虫频繁打扰而设置的一种技术协议。滥用Robots协议,其结果必将造成行业竞争壁垒,导致互联网行业内不公平竞争泛滥,进而导致搜索引擎给网民展现不完整的搜索结果,阻碍搜索市场的自由竞争。

































 粤公网安备 44140302000013号
粤公网安备 44140302000013号